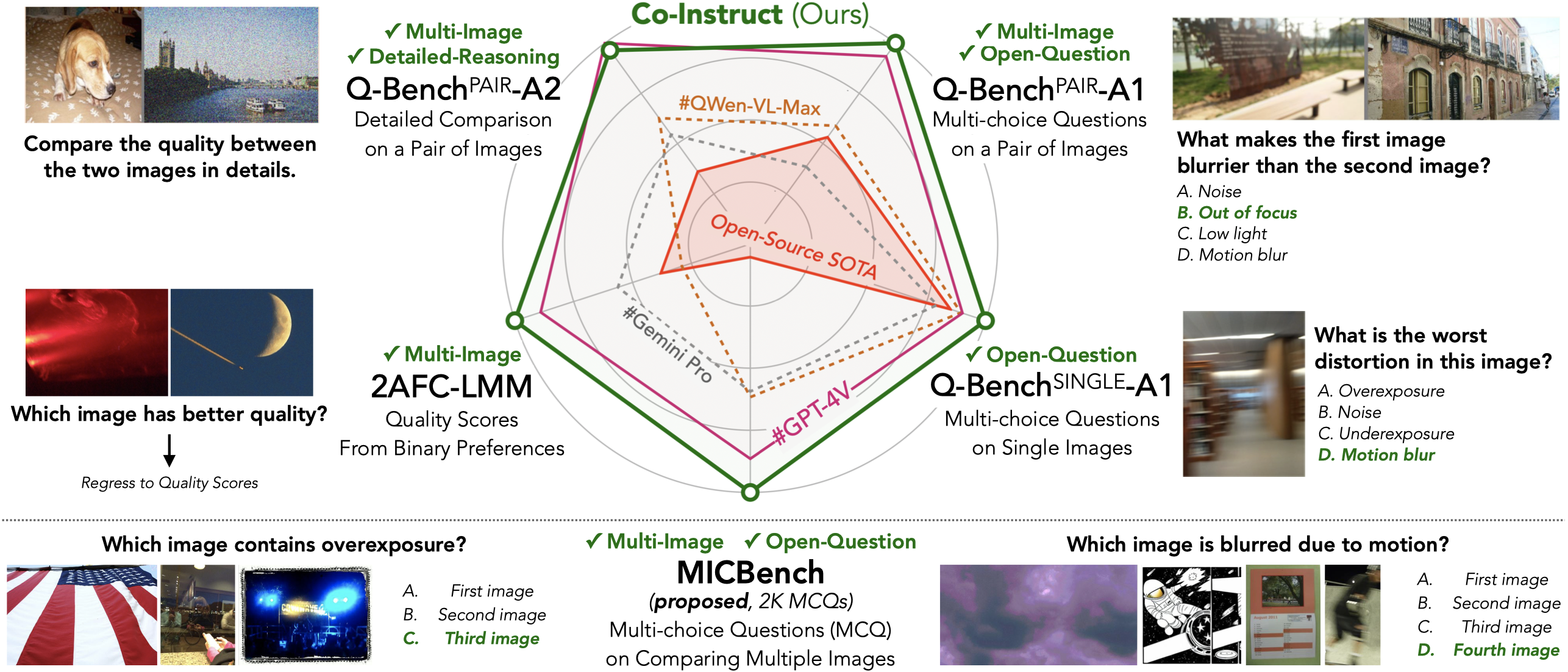
Abstract
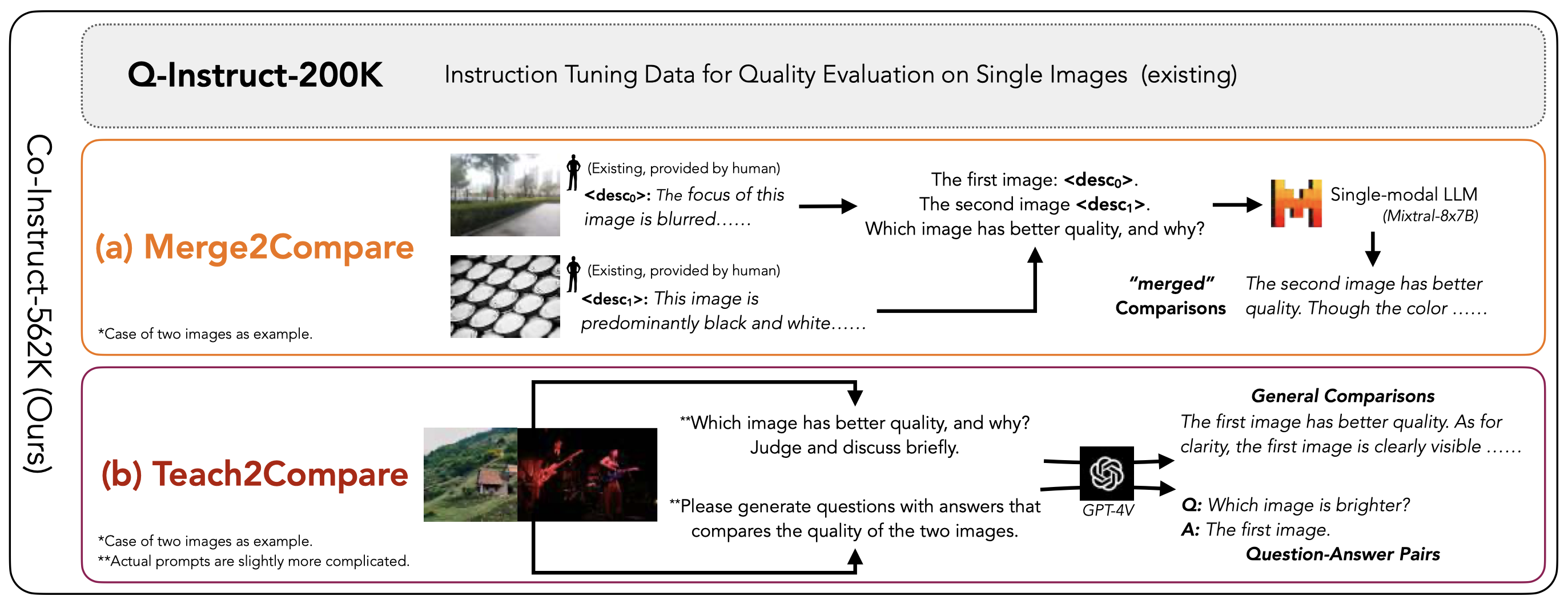
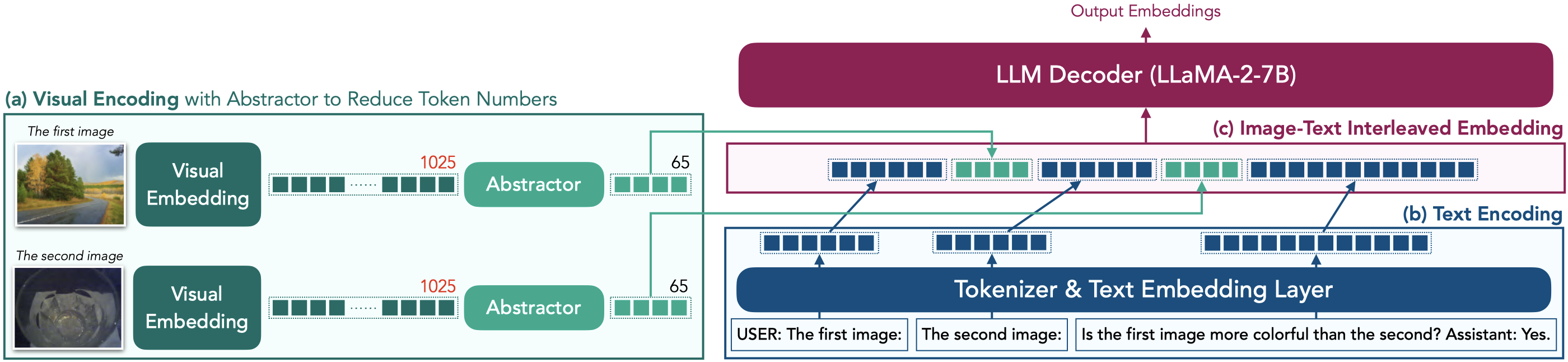
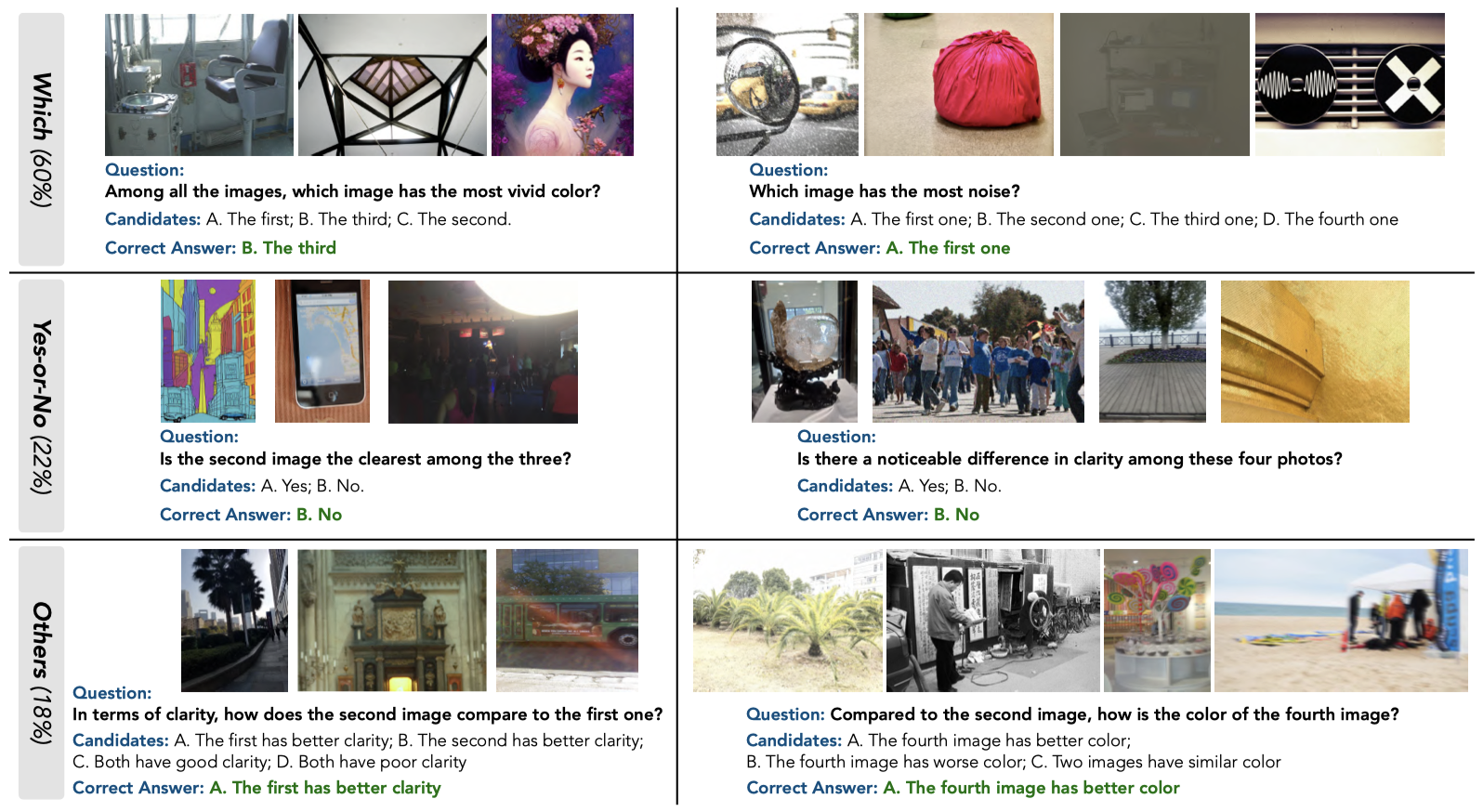
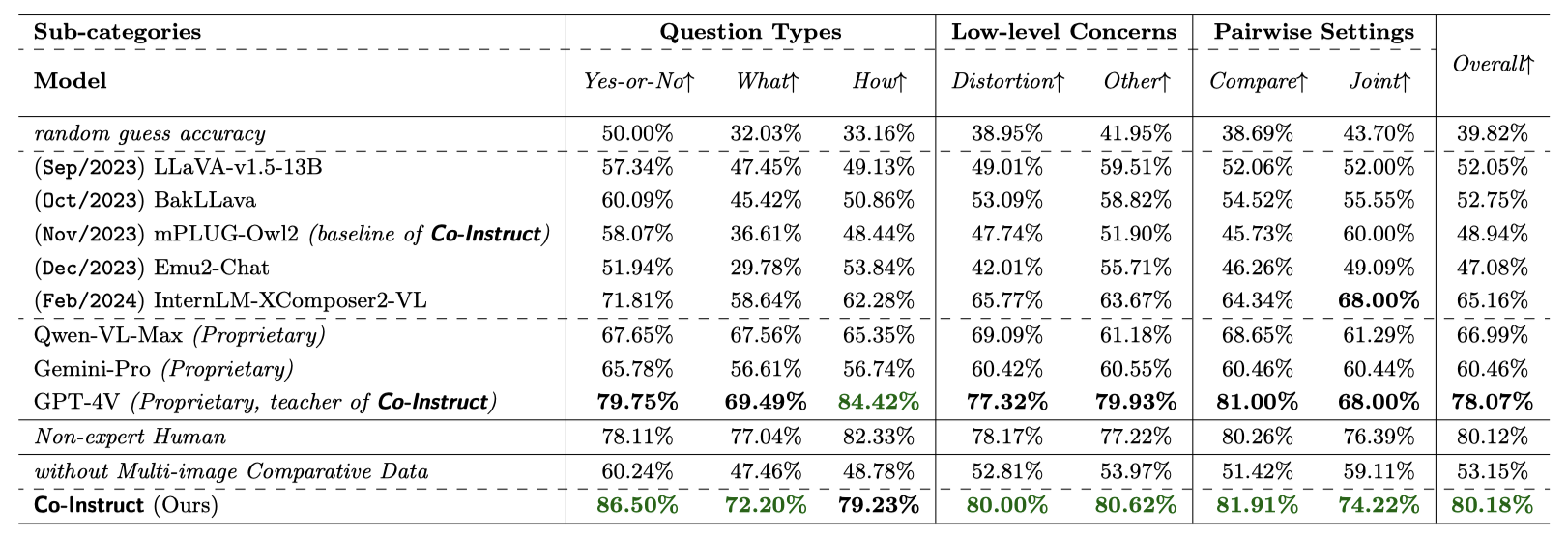
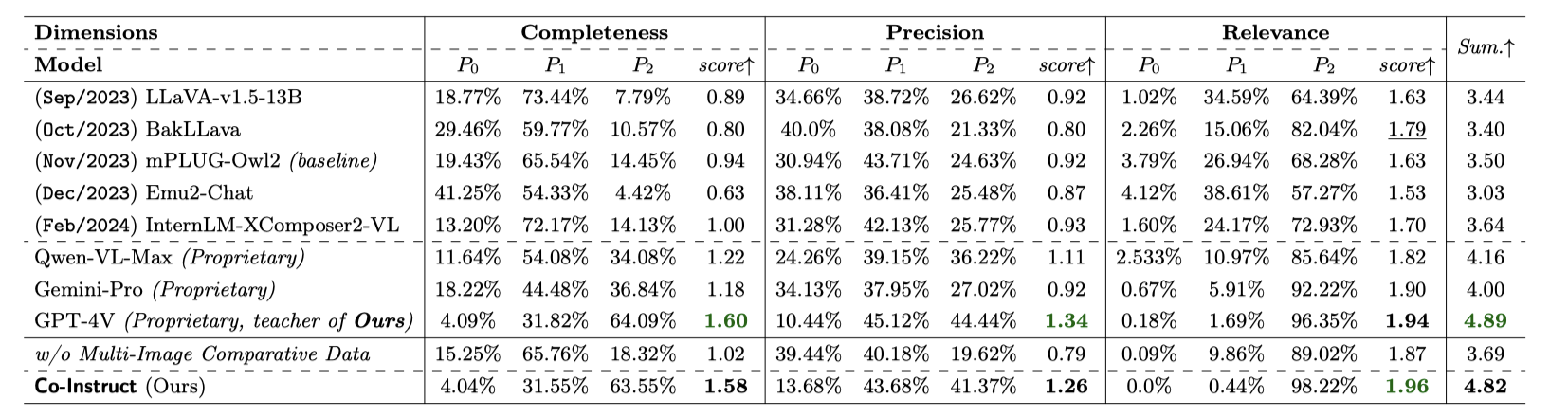
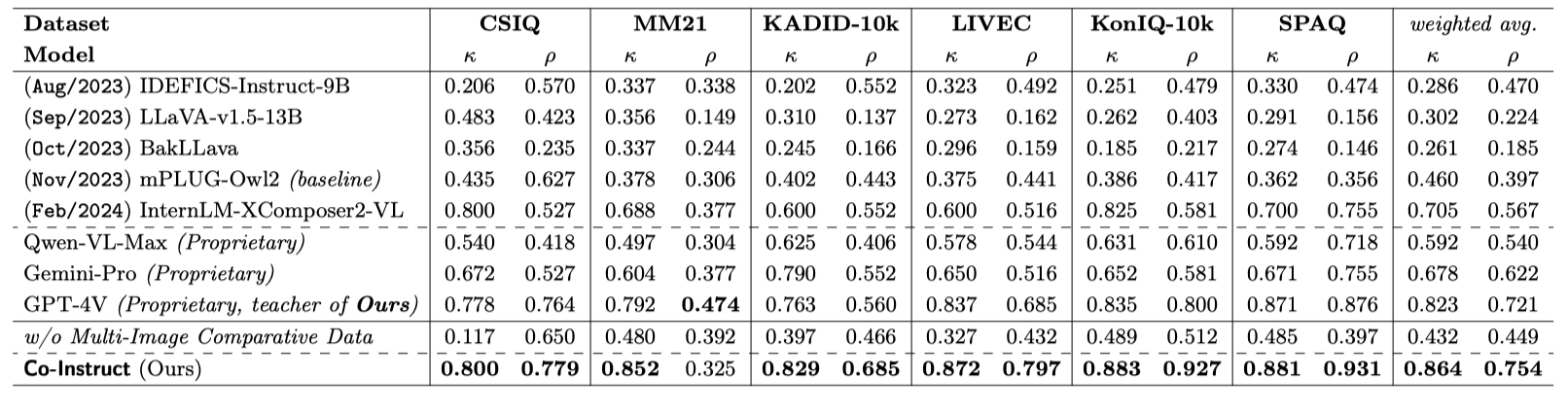
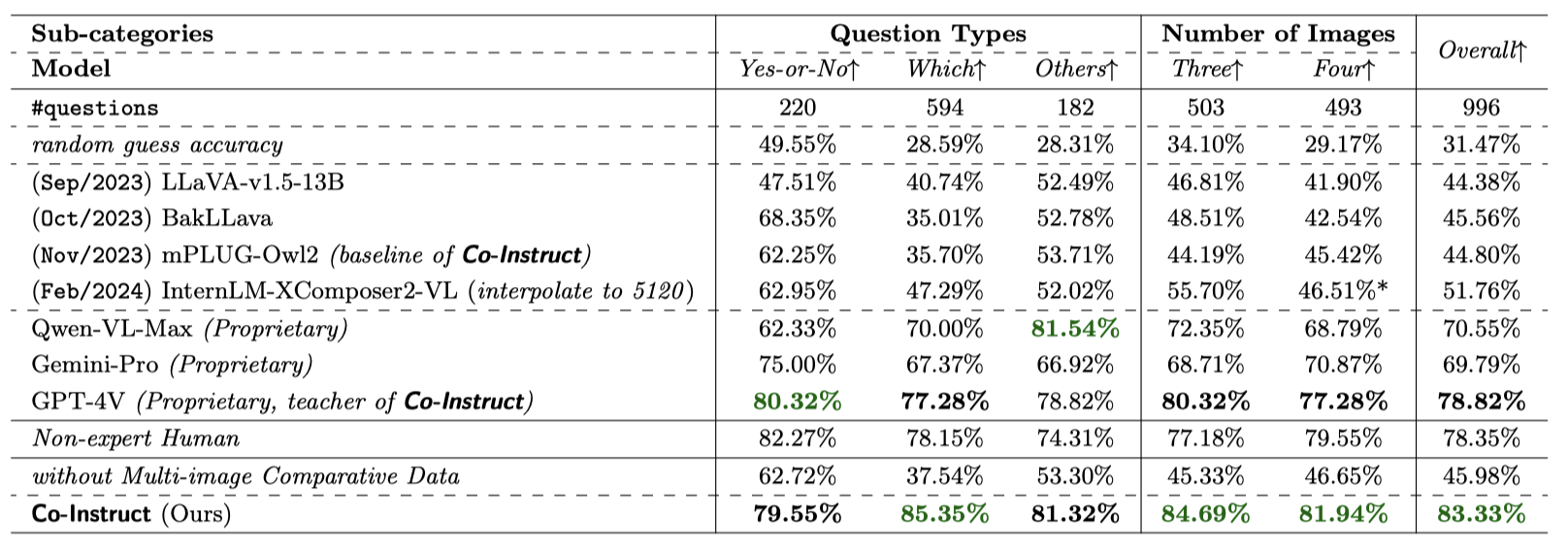
Comparative settings (e.g., pairwise choice, listwise ranking) have been adopted by a wide range of subjective studies for image quality assessment (IQA), as it inherently standardizes the evaluation criteria across different observers and offers more clear-cut responses. In this work, we extend the edge of emerging large multi-modality models (LMMs) to further advance visual quality comparison into open-ended settings, that 1) can respond to open-range questions on quality comparison; 2) can provide detailed reasonings beyond direct answers. To this end, we propose the Co-Instruct. To train this first-of-its-kind open-source open-ended visual quality comparer, we collect the Co-Instruct-562K dataset, from two sources: (a) LMM-merged single image quality description, (b) GPT-4V "teacher" responses on unlabeled data. Furthermore, to better evaluate this setting, we propose the MICBench, the first benchmark on multi-image comparison for LMMs. We demonstrate that Co-Instruct not only achieves 30% higher superior accuracy than state-of-the-art open-source LMMs but also outperforms GPT-4V (its teacher) on both existing related benchmarks and the proposed MICBench."